반응형
- AWS에서 개발한 EKS 환경에서 클러스터를 자동으로 조정하기 위한 프로비저닝 도구이다.
- 파드 생성 시 pending 생길 수 있다. (파드가 크거나, 자리가 없을 시)
- 노드 그룹을 통해 노드를 추가한다.
- AWS : AutoScalingGroup으로 추가할 수 있다.
- 바인딩 되지 못한 파드를 프로비저닝 하기 위해서는 노드를 하나 생성해야 한다.
Karpenter
- watch API : 몇개의 자원이 필요한지 판단하여 파드를 프로비저닝한다.
- 동작 방식 : pod auto scaling → pending pods → ( 생략함 : cluster auto scaler → auto scaling Group ) → EC2 Fleet (instant)
- NodePool
- EC2NodeClass
- EC2와 긴밀히 통합, EC2 Fleet API, ASGs가 없음
- 쿠버네티스 네이티브
- 4가지의 동작
- Watching : k8s가 생성한 Event를 Watch API를 이용해 전달 받는다.
- Evaluating : Pod spec에 있는 constaints를 만족하는 node를 scheduling한다.
- Provisioning : Pod의 requirments를 만족하는 Node를 provisioning한다.
- Disrupting : 더이상 필요하지 않는 노드를 삭제한다.
Consolidation 기능
- 실행 중인 Pod를 클러스터 내 활용도가 낮은 노드에 자동으로 재스케줄링
- 활용도가 낮은 노드를 대체하기 위해 보다 비용 효율적인 compute resource를 새롭게 실행
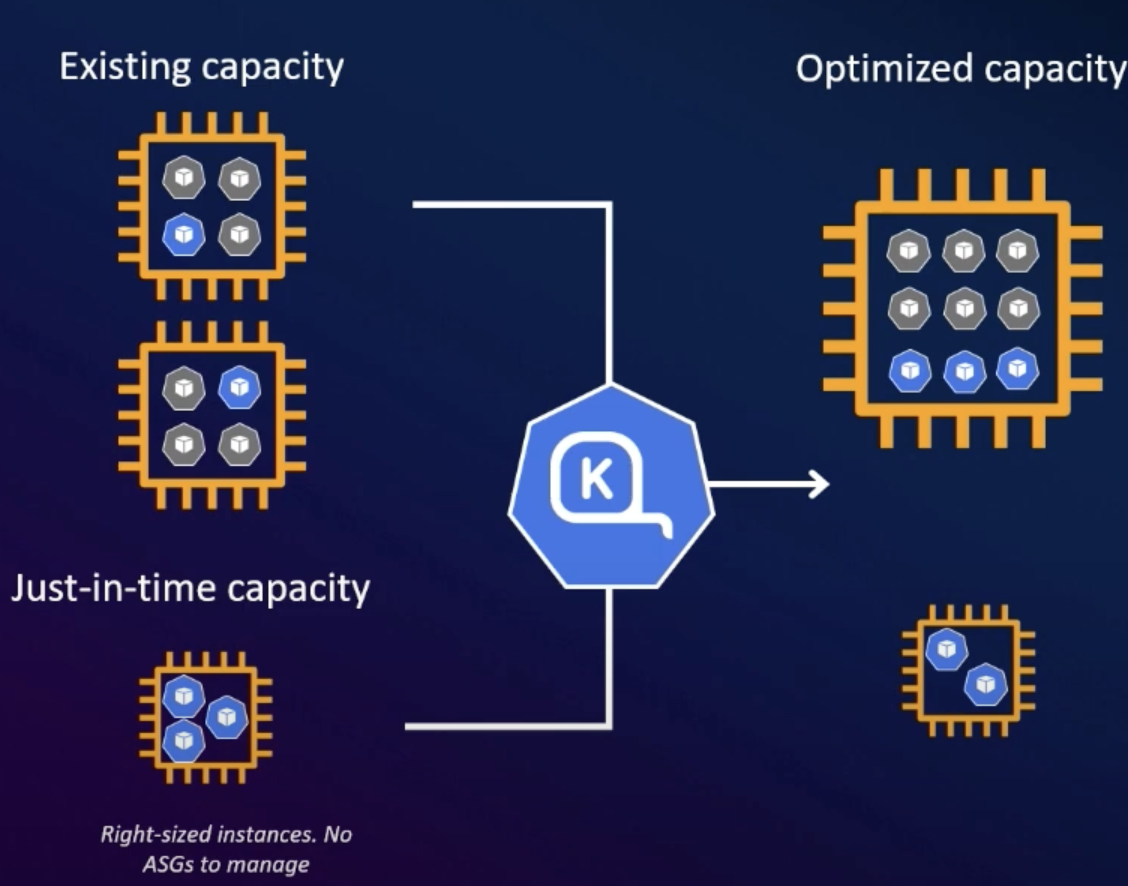
제공 기능
- 데이터 플레인 확장
- 오토 스케일링 제공
- 머신 러닝 및 생성형 AI 등 다양한 워크로드 적용에 비용 최적화, 운영 효율화적으로 활용 가능하다.
- 컴퓨팅 유연성
- 인스턴스 유형 선언 가능
- 속성 기반 요구 사항 정의 → 사이즈, 패밀리, 세대, CPU 아키텍처
- 리스트가 없는 경우 → 베어 메탈을 제외한 모든 인스턴스 유형 고려
- 생성할 수 있는 EC2 인스턴스 수 제한
- 가용 영역 (AZ)
- 모든 가용 영역
- 지정된 가용 영역
- 인스턴스 유형 선언 가능
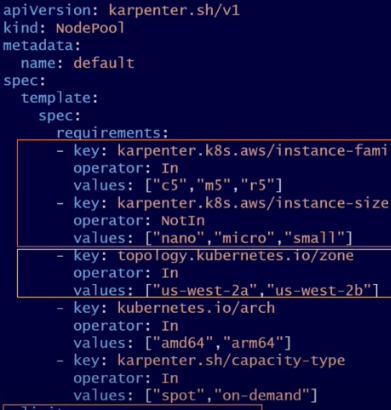
NodePool - 워크로드 스케줄링
- 워크로드별 요구 사항
- 특정 가용 영역
- 특정 유형의 프로세서, 하드웨어 (ex. GPU, ARM)
- 특정 구매 옵션 (온디맨드 및 스팟 인스턴스)
- 표준 쿠버네티스 스케줄링 메커니즘
- 노드 셀렉터 (Node Selectors)
- 노드 어피니티 (Node Affinity)
- 테인트와 톨러레이션 (Taints and Tolerations)
- 토폴로지 분배 (Topology Spread)
→ 파드의 스케줄링 제약 조건은 NodePool에 정의된 요구 사항을 충족
- 구성 전력
- 단일 구성
- 단일 NodePool을 여러 팀과 워크로드에서 사용
- 구성 예시
- Gravition과 x86 컴퓨팅을 단일 NodePool로 정의
- pod 스펙을 통해 원하는 컴퓨팅 노드 선택
- 복수 구성
- 다양한 목적에 맞게 컴퓨팅 환경 분리
- 구성 예시
- 하드웨어 비용
- 보안 격리
- 팀 분리
- 서로 다른 이미지 사용
- 성능 간섭 방지를 위한 테넌트 격리
- 가중치 구성
- NodePool 가중치 구성을 통해 우선 순위 지정
- 구성 예시
- Reserved Instance 및 Saving Plan
- 기본 컴퓨팅 환경 정의 (스팟 / 온디맨트, Gravition / x86)
- 단일 구성
Karpenter - Scheduling
- Watching
- k8s가 생성한 Event를 Watch API를 이용해 전달 받는다.
- Evaluating
- Pod spec에 있는 constaints를 만족하는 node를 scheduling한다.
- Provisioning
- Pod의 requirments를 만족하는 Node를 provisioning한다.
- Disrupting
- 더이상 필요하지 않는 노드를 삭제한다.
2. Evaluating - Batch Window
- karpenter는 파드가 하나씩 늘어날 때마다 node를 만들어내면 너무 작은 node가 많이 만들어지는 것을 방지하기 위해 batch window라는 개념을 갖고 있다.
- Provision 할 파드가 발생하는, batcher.wait에서 BatchldleDuration(1초) 만큼 대기하고 Node를 만드는 함수(CreateNodeClaims)를 호출한다.
- 이 기간 (1초) 중에 다른 파드가 추가되면 또 1초를 대기하며, 최대 대기 시간 (BatchMaxDuration)인 10초가 지나면, CreateNodeClaims를 호출한다.
2. Evaluating - Bin Packing
- 스케줄링과 빈패킹 시뮬레이션 결합
- 노드풀과 파드 요구 사항의 교집합 정의
- 노드클래스 요구 사항 (서브넷, ODCRs)
- 호스트 포트, 볼륨 토폴리지, 볼륨 사용량 고려
- 데몬셋 스케줄링 고려
- 더 적은 수의, 보다 큰 인스턴스 타입 선호
- 사용률 최적화가 아닌 비용 최적화
- 인스턴스 유형 디스커버리 → 비용 순으로 인스턴스 정렬 → 요구사랑 교집합 → 재사용, 스케일업 또는 생성
4. Disrupting - 노드 중단
- 종류 : Drift, Expiration, Consolidation, Interruption
- Drift : 돌고 있는 것과 선언한 스펙이 맞지 않을 때, 스펙 해시(테인트, 라벨)
- Expiration : 특정 기간 이후 노드 삭제
- Interruption : 스팟 용량, 헬스 이벤트
- Consolidation : 비용 최적화
- PDB을 활용한 고가용성 유지
- do-not-disrupt: true
- 표준화된 중단 워크플로우
- 후보 노드 선정 기준
- 노드 중단 가능 여부
- 파드 중단 최소화
- 오래된 노드 선호
- 후보 노드 식별 → 대체 노드 생성 → 후보 노드 드레이닝 → 후보 노드 종료
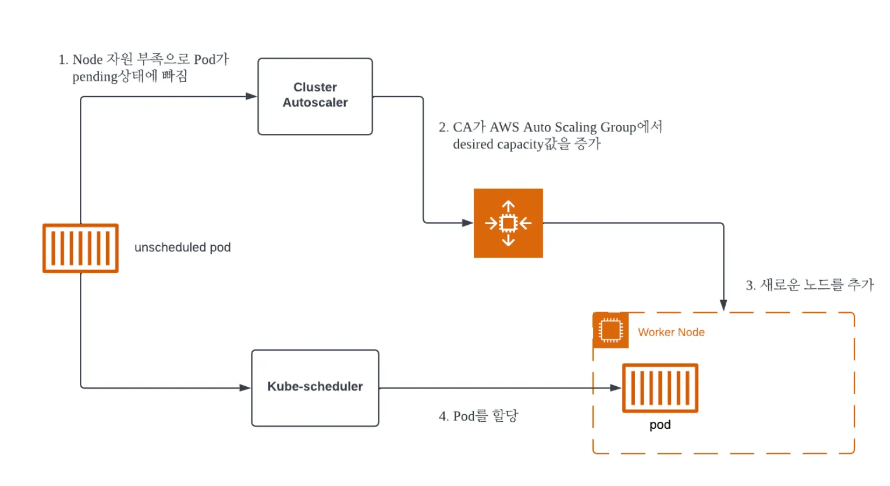
기존 Cluster AutoScaler 동작 원리
- Node 자원 부족으로 pod가 pending상태에 빠짐
- CA가 AWS Auto Scaling Group에서 desired capacity 값을 증가
- 새로운 노드를 추가
- pod를 할당
- CA 방식은 AWS 리소스인 ASG에 의존도가 높기 때문에 node 추가가 오래 걸림
- ASG(인스턴스 조절)과 EKS (노드 관리)의 관리 주체가 다름 (동기화 문제)
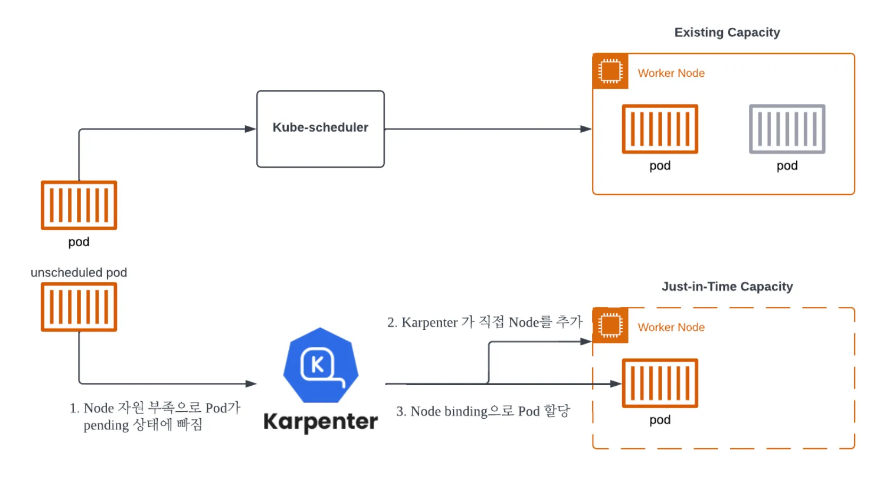
Karpenter 동작 원리
- Node 자원 부족으로 pod가 pending 상태에 빠짐
- karpenter가 직접 node를 추가
- node binding으로 pod 할당
- 추가된 node가 ready 상태가 되면 kerpenter는 kube-scheduler를 대신하여 pod의 node binding 요청도 수행한다.
- CA에 비해 훨씬 빠른 구조를 가지고 있다.
- 모든 워커 노드는 kerpenter에 의해 라이프 사이클이 결정된다.
Karpenter의 장점
- 운영 부담 절감
- 설치 후 Provisioner라는 CRD만 구성해주면 사용 가능하다.
- Provisioner를 용도별로 구성하면 별도로 관리형 Node Group을 생성하고 운영할 필요가 없어 운영 부담이 절감된다.
- 신속한 Node 추가와 제거
- Node의 추가 속도가 빨라진다. (약 ~1.5분)
- Node제거에 대해서 ttlSecondsAfterEmpty 파라미터 값을 정의하여 사용 가능
- 자동 Node 롤링
- ttlSecondsUntilExpired 파라미터를 정의하여 Node를 주기적으로 rolling Update 가능
반응형
'Cloud' 카테고리의 다른 글
| [k8s] EKS에서 Karpenter 사용하기 (2) (1) | 2025.01.05 |
|---|---|
| [k8s] EKS에서 Karpenter 사용하기 (1) (0) | 2025.01.05 |
| [monitoring] Node Exporter, Prometheus, Grafana로 모니터링 구축 (prometheus 메트릭을 cloudwatch로 전송하기) (1) | 2024.12.11 |
| 클라우드 개론 (0) | 2024.11.28 |
| 클라우드 과정 목표 (3) | 2024.11.28 |